The machine learning lifecycle is developing, deploying, and maintaining a machine learning model for a particular application. The typical lifecycle includes:

Establish a business objective
The first step in the process starts with determining the business objective of implementing a machine learning model. For instance, a business objective for a lending firm can be predicting credit risk in a certain number of loan applications.
Data Gathering & Annotation
The next stage in the machine learning life cycle is data collection and preparation, guided by the defined business goal. This is usually the longest stage in the development process.
Developers will select data sets for the model’s training and testing based on the type of machine learning model. Take credit risk as an example. If the lender wants to gather information from scanned documents, they can use an image recognition model; for data analysis, It would be snippets of numerical or text data gathered from loan applicants.
The most crucial stage after data collection is annotation “wrangling.” Modern AI (Artificial Intelligence) models require highly specific data analysis and instructions. Annotation helps developers increase consistency and accuracy while minimizing biases to avoid malfunction after deployment.
Model Development & Training
The building process is the most code-intensive element of the machine learning life cycle. This stage will be mostly managed by the development team’s programmers, who will design and assemble the algorithm effectively.
However, developers must constantly check things during the training process. It is critical to detect any underlying biases in the training data as quickly as possible. Assume the image model cannot recognize documents, forcing it to misclassify them. In this situation, the parameters should instruct the model to focus on patterns in the image rather than pixels.
Test & Validate Model
The model should be completely functional and running as planned by the testing phase. A separate validation dataset is used for evaluation during training. The goal is to see how the model reacts to data it has never seen before.
Model Deployment
It is finally time to deploy the machine learning model after training. At this point, the development team has done everything possible to ensure that the model functions optimally. The model can operate with uncurated low latency data from real users and is trusted to assess it accurately.
Returning to the credit risk scenario, the model should reliably anticipate loan defaulters. The developers should be satisfied that the model will meet the lending firms’ expectations and perform properly.
Model Monitoring
The model’s performance is tracked after deployment to ensure it keeps up over time. For instance, if a machine learning model for loan default prediction was not regularly refined, it could not detect a new default type. It is critical to monitor the models to detect and correct bugs. Any key findings from the monitoring can be used to improve the model’s performance.
1. Amazon SageMaker
- Amazon SageMaker provides machine learning operations (MLOps) solutions to help users automate and standardize processes throughout the ML lifecycle.
- It enables data scientists and ML engineers to increase productivity by training, testing, troubleshooting, deploying, and governing ML models.
- It helps integrate machine learning workflows with CI/CD pipelines to reduce time to production.
- With optimized infrastructure, training time can be reduced from hours to minutes. The purpose-built tools can increase team productivity by up to tenfold.
- It also supports the leading ML frameworks, toolkits, and programming languages like Jupyter, Tensorflow, PyTorch, mxnet, Python, R, etc.
- It has security features for policy administration and enforcement, infrastructure security, data protection, authorization, authentication, and monitoring.
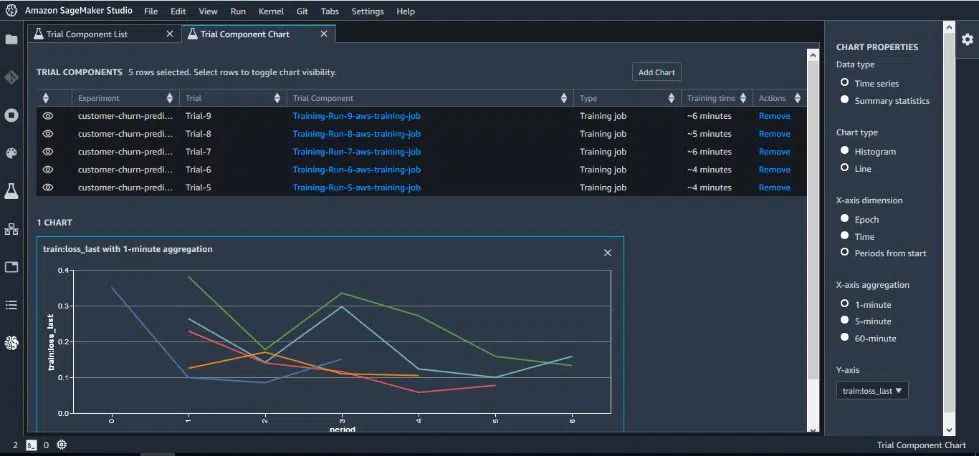
Source: Amazon
2. Azure Machine Learning
- Azure Machine Learning Services is a cloud-based platform for data science and machine learning.
- With built-in governance, security, and compliance, users can run machine learning workloads anywhere.
- Rapidly create accurate models for classification, regression, time-series forecasting, natural language processing, and computer vision tasks.
- Leveraging Azure Synapse Analytics, users can perform interactive data preparation with PySpark.
- Enterprises can boost productivity with Microsoft Power BI and services like Azure Synapse Analytics, Azure Cognitive Search, Azure Data Factory, Azure Data Lake, Azure Arc, Azure Security Centre, and Azure Databricks.
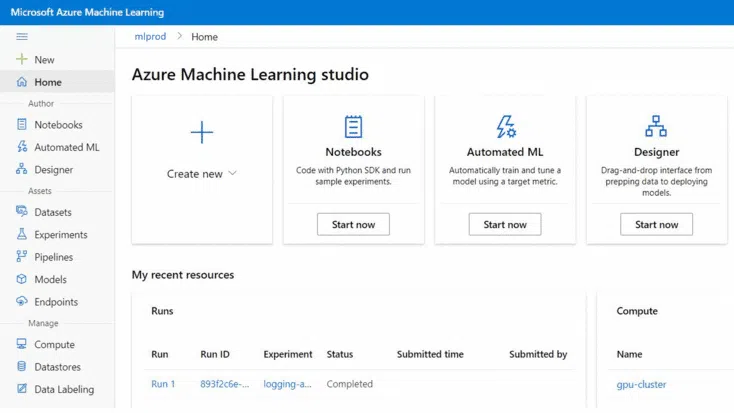
Source: Microsoft
3. Databricks MLflow
- Managed MLflow is built on top of MLflow, an open-source platform developed by Databricks.
- It helps the users manage the complete machine learning lifecycle with enterprise reliability, security, and scale.
- MLFLOW tracking uses Python, REST, R API, and Java API to automatically log parameters, code versions, metrics, and artifacts with each run.
- Users can record stage transitions and request, review, and approve changes as part of CI/CD pipelines for improved control and governance.
- With access control and search queries, users can create, secure, organize, search, and visualize experiments within the Workspace.
- Quickly deploy on Databricks via Apache Spark UDF for a local machine or several other production environments such as Microsoft Azure ML and Amazon SageMaker and build Docker Images for Deployment.
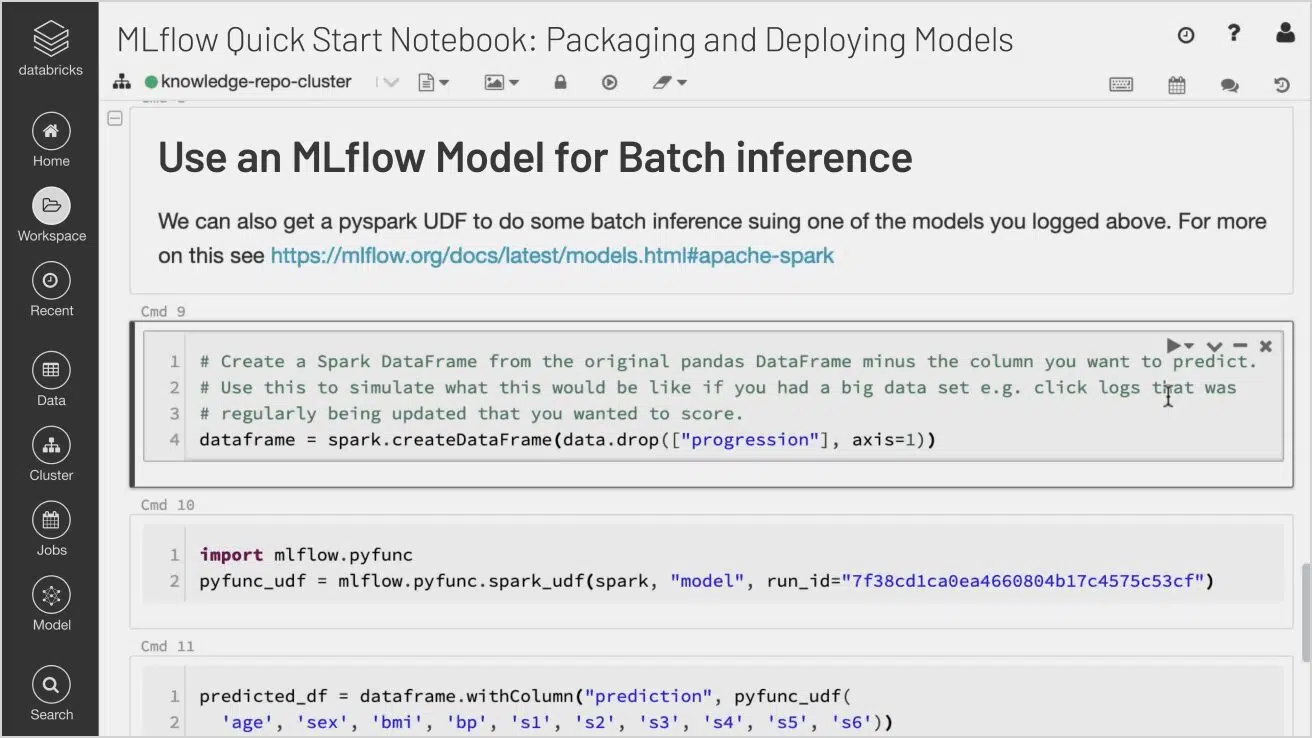
Source: Databricks
4. TensorFlow Extended (TFX)
- TensorFlow Extended is a production-scale machine learning platform developed by Google. It provides shared libraries and frameworks for integrating machine learning into the workflow.
- TensorFlow extended allows users to orchestrate machine learning workflows on various platforms, including Apache, Beam, and KubeFlow.
- TensorFlow is a high-end design for improving TFX workflow, and TensorFlow helps users analyze and validate machine learning data.
- TensorFlow Model Analysis offers metrics for huge amounts of data distributed and helps users evaluate TensorFlow models.
- TensorFlow Metadata provides metadata that can be generated manually or automatically during data analysis and is useful when training machine learning models using TF.
Source: TensorFlow
5. MLFlow
- MLFlow is an open-source project that aims to provide a common language for machine learning.
- It is a framework for managing the full machine learning lifecycle
- It provides an end-to-end solution for data science teams
- Users can easily manage models in production or on-premises using Hadoop, Spark, or Spark SQL clusters running on Amazon Web Services (AWS).
- MLflow provides a collection of lightweight APIs that can be combined with any existing machine learning application or library (TensorFlow, PyTorch, XGBoost, etc.).
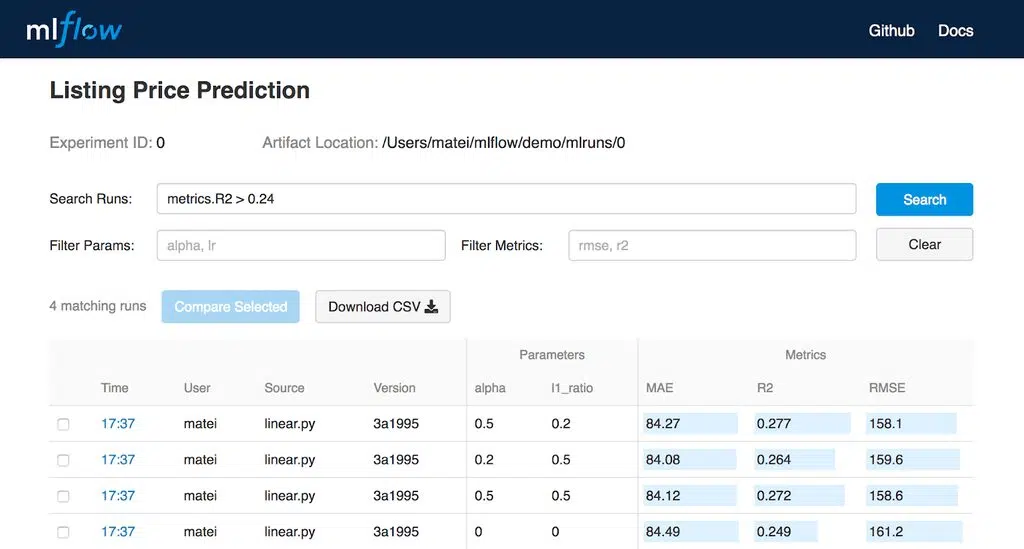
Source: MLFlow
6. Google Cloud ML Engine
- Google Cloud ML Engine is a managed service that makes it easy to build, train and deploy machine learning models.
- It provides a unified interface for training, serving, and monitoring ML, models.
- Bigquery and cloud storage help users prepare and store their datasets. Then they can label the data with a built-in feature.
- The Cloud ML Engine can perform hyperparameter tuning that influences the accuracy of predictions.
- Users can complete the task without writing any code using the Auto ML feature with an easy-to-use UI. Also, Users can run the notebook for free using Google Colab.
Source: Google
7. Data Version Control (DVC)
- DVC is an open-source data science and machine learning tool written in Python.
- It is designed to make machine learning models shareable and reproducible. It handles large files, data sets, machine learning models, metrics, and code.
- DVC controls machine learning models, data sets, and intermediate files and connects them with code. Stores file contents on Amazon S3, Microsoft Azure Blob Storage, Google Cloud Storage, Aliyun OSS, SSH/SFTP, HDFS, etc.
- DVC outlines the rules and processes for collaborating, sharing findings, and collecting and running a completed model in a production environment.
- DVC can connect ML steps into a DAG (Directed Acyclic Graph) and run the full pipeline end-to-end.
Source: Data Version Control (DVC)
8. H2O Driverless AI
- H2O Driverless AI is a cloud-based machine learning platform that allows you to build, train and deploy machine learning models using just a few clicks.
- It supports R, Python, and Scala programming languages.
- Driverless AI can access data from various sources, including Hadoop HDFS, Amazon S3, and others.
- Driverless AI automatically picks data plots based on the most relevant data statistics, develops visualizations, and provides data plots that are statistically significant based on the most important data statistics.
- Driverless AI can be used to extract information from digital photos. It allows for using solitary photos and images combined with other data types as predictive characteristics.
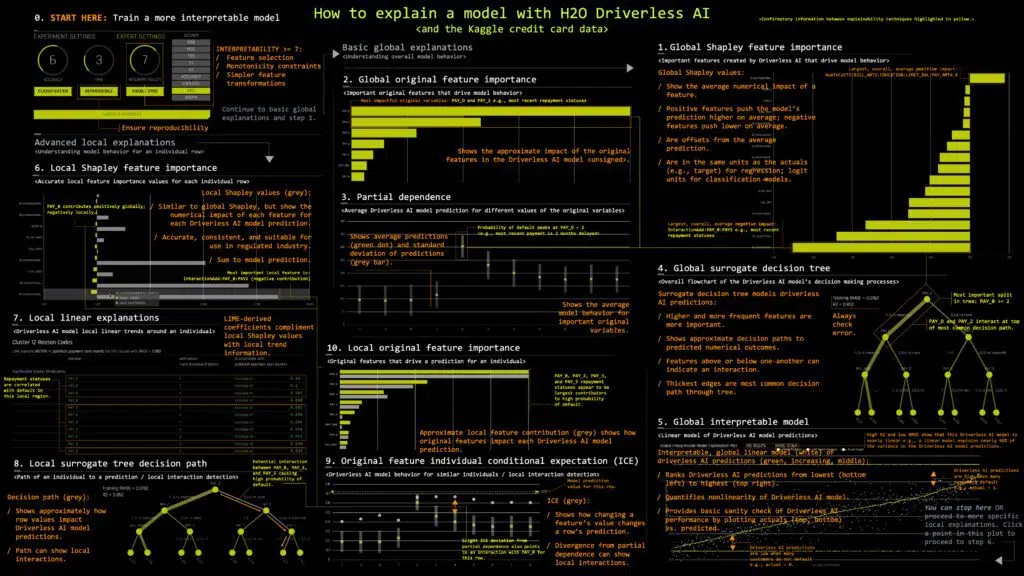
Source: H2O Driverless AI
9. Kubeflow
- Kubeflow is the cloud-native platform for machine learning operations – pipelines, training, and deployment.
- It is a part of the Cloud Native Computing Foundation (CNCF), including Kubernetes and Prometheus.
- Users can leverage this tool to build their own MLOps stack using any number of cloud providers like Google Cloud or Amazon Web Services (AWS).
- Kubeflow Pipelines is a comprehensive solution for deploying and managing end-to-end ML workflows.
- It also extends the support for PyTorch, Apache MXNet, MPI, XGBoost, Chainer, and more. It also integrates with Istio, Ambassador for ingress, and Nuclio for managing data science pipelines.
Source: Kubeflow
10. Metaflow
- Metaflow is a Python-based library created by Netflix to help data scientists and engineers manage real-world projects and increase productivity.
- It provides a unified API to stack, which is required to execute data science projects from prototype to production based.
- Users can efficiently train, deploy, and manage ML models; Metaflow integrates Python-based Machine Learning, Amazon SageMaker, Deep Learning, and Big Data libraries.
- Metaflow includes a graphical user interface that helps the user design the work environment as a directed acyclic graph (D-A-G).
- It can automatically version and track all experiments and data.
Source: Metaflow
New in the Market
Snowpark by Snowflake
- Snowpark for Python offers a simple way for data scientists to perform DataFrame-style programming against the Snowflake data warehouse.
- It can set up full-fledged machine-learning pipelines to run repeatedly.
- Snowpark plays a significant role in the last two phases of the ML Lifecycle (model deployment and monitoring).
- Snowpark provides an easy-to-use API for querying and processing data in a data pipeline.
- Since its introduction, Snowpark has evolved into one of the best data applications, making it easy for developers to build complex Data Pipelines.
- With Snowflake’s vision for the future and extensible support, the application will be the best choice for solving complex data and machine-learning problems in the upcoming years.