
Understand the Real Problem
The current situation is like this: an automation framework was built when APIs were limited and manageable. That time, automation was working well. As APIs are growing, the team shipped faster, and the time frame automation gradually fell behind. A few months later, your existing scripts for APIs no longer work due to parameters being updated, and test data referencing schemas have been changedand validation was silently skipped because nobody had time to update them in the agile model.
This is not team failure. It is a structural problem with the traditional approach to API test automation. When tests are authored manually, their maintenance cost grows directly with the rate of API change. In a fast-moving model, that cost becomes unsustainable.

Figure 1 — The five places manual API testing drains QA time every sprint
The Core Shift: Treat Swagger as Active Documentation
Most teams use their Swagger documentation as a reference — something developers write and QA reads. The shift that makes autonomous testing possible is treating it as an input to a test generation system rather than a document to read.
To make this easy to understand, we can break it down into simpler, clearer terms. Since a Swagger specification already includes every detail about how an API works, we can use it to build a custom-fit automation solution for your project.
In practice, when an API changes with a spec, the official plan updates automatically. Instead of wasting time manually fixing outdated test scripts, the testing tool builds fresh, up-to-date tests directly from the new plan. This eliminates ongoing maintenance work.

Figure 2 — Manual approach versus autonomous framework: the same test outcomes, radically different effort
How to Structure the Framework
An autonomous API testing framework built for Swagger with five components. Each layer has a specific responsibility, and they chain together in sequence for every test cycle.
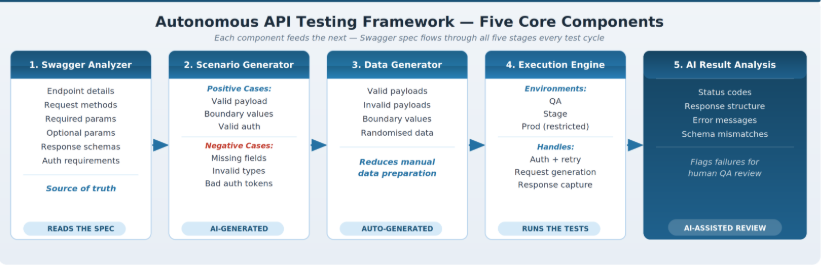
Figure 3 — The five-component pipeline from Swagger spec to AI-assisted result analysis
1. Swagger Analyzer
This is the starting point. The analyzer reads the APIs and extracts the structured information which are needed to generate test cases with endpoint paths, HTTP methods, required and optional parameters, request body schemas, expected response structures, and authentication requirements.
Here, the main point is that the quality of everything downstream depends on the quality of this input. An incomplete or inconsistently written spec will produce incomplete test coverage. Before onboarding any API to an autonomous framework, run end-to-end check on its Swagger documentation first.
2. Scenario Generator
After the AI reads the API document, it creates two types of test scenarios for all the endpoints. 1. Positive Scenario: valid payloads, correct authentication, boundary value inputs 2. Negative Scenario: missing mandatory fields, wrong data types, expired tokens, empty request bodies, and unexpected parameter values.
Negative test case generation is where AI tends to deliver the most value compared to manual validation. Writing thorough negative test cases by hand is repetitive and easy to automate. A generator working from the full parameter schema will cover combinations a human tester would skip.
3. Test Data Generator
For any test scenarios that need data to run. This component will create the actual payloads — valid ones, intentionally broken ones, boundary cases, and randomized variants for full coverage. For APIs with complex request bodies, automated data generation saves a good amount of time compared to building test datasets manually.
One practical note: if your APIs interact with multiple environments for data stores, establish strict data boundaries early in this layer. It is much harder to add after the fact.
4. Execution Engine
The generated test scenarios are executed against the target environment, mostly for QA and Stage, for Production, access is restricted to read-only or smoke-level validation. The AI engine logs you in, makes the calls, saves the results, and tries again if something goes wrong.
Keep this layer very clear. The job of this layer is to receive what is given and record what comes back. The intelligence belongs in the components around it — not in the executor itself.
5. AI Result Analysis
Rather than manual review for response logs, AI will do analysis results and will raise anything that looks wrong/failed, like unexpected status codes, response structure drift, error messages that do not match documented behavior, and schema mismatches between the spec and what is received in response. This is a priority list of failures for the QA team to review, it is not just a strict Pass or Fail.
This difference is important. AI points out things to investigate, but humans make the final release decision. The final call is up to the QA expert.
What AI can and cannot do
It is important to understand the reality of the project from the beginning. AI performs well on the parts of API testing that are high-volume, rule-based, and derivable from the spec. It does not perform well on the parts that require understanding what the API is supposed to do in a business context.

Figure 4 — Where AI delivers value versus where human expertise remains essential
Scenario generation and result analysis layers perform well from the starting point. Standard validations, negative case coverage, and schema drift detection AI can do these tasks perfectly at a speed that humans just can’t match, across hundreds of endpoints.
AI needs exact guidance, it cannot guess what to do that is not captured in the spec. Business rules that live in someone’s head. Workflow dependencies across services. Customer-specific edge cases that the team just knows about but nobody wrote down. AI will generate technically valid tests for these areas, but miss the expectation behind them.


