Everyone’s talking about models. Which one’s smartest, which one’s affordable, which one just dropped this week? Fair enough, it’s the fun part.
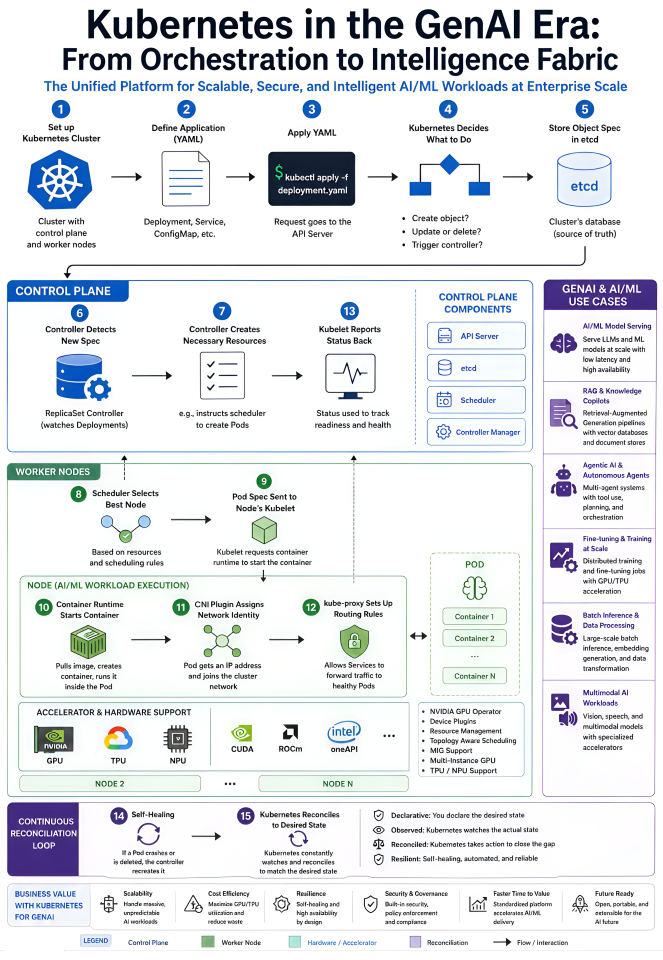
But if you’ve actually tried to put GenAI into production at a company, you know the model is maybe 20% of the problem. The other 80% is the boring stuff, keeping it running, scaling it when traffic spikes, paying for GPUs you’re not wasting, hooking it up to your data, and making sure security doesn’t have a meltdown.
And that’s where Kubernetes quietly does most of the heavy lifting.
Why Kubernetes Matters More Now
1. You’re juggling very different kinds of compute
Training, fine-tuning, and inference don’t behave anything alike. Training runs for days and eats bandwidth. Fine-tuning shows up in bursts. Inference has to be fast and always on.
You can’t just throw all of that on the same pile of hardware and hope for the best. Kubernetes schedules across GPUs, TPUs, and NPUs, packs jobs efficiently, and keeps teams from stepping on each other. Pair it with something like the NVIDIA GPU Operator and your expensive accelerators stop being one team’s pet project — they become a shared resource everyone can actually use.
Result: you get more out of the hardware you already paid for.
2.AI traffic is wildly unpredictable
A copilot might be dead quiet at 3am and then get hammered when Europe wakes up. A batch embedding job needs 200 GPUs for an hour, then nothing. If you size for the peak, you’re burning money. If you size for the average, you fall over.
KEDA, HPA, scale-to-zero, queue-based scaling — Kubernetes has tools for this exact problem. Capacity moves with demand instead of sitting idle.
Result: you stop paying for GPUs that aren’t doing anything.
3. Models become real services, not science projects
I’ve seen too many teams stand up a model behind a hand-rolled Flask app and call it a day. It works, until it doesn’t, and then nobody can roll it back.
KServe, Seldon, and similar tools give you proper serving — versioning, canary rollouts, gRPC and REST out of the box, observability you don’t have to wire up yourself. Once you have more than one model in prod, this stops being a nice-to-have.
Result: swapping or rolling back a model is a config change, not a fire drill.
4. Agents need real orchestration
GenAI isn’t one API call anymore. It’s a planner calling tools, fanning out to retrieval, calling other agents, double-checking itself. Lots of moving parts, lots of ways to fail.
Argo and Tekton handle this kind of workflow well — retries, parallelism, checkpointing, the whole thing. When a node dies mid-run, you don’t lose forty minutes of work.
Result: complex pipelines actually finish.
5. Your data and your AI need to live together
A model is only as good as what you feed it. That means vector DBs for RAG, Kafka for streaming, Spark or Ray for the heavy lifting. If those live in one world and your models live in another, you spend half your time gluing them together.
Running everything on Kubernetes means they share the same networking, identity, storage, and monitoring. Less duct tape.
Result: the path from raw data to a model response is one platform, not five.
6. Security and governance can’t be afterthoughts
GenAI brings its own zoo of problems — prompt injection, data leaking through retrieval, agents calling tools they shouldn’t. Compliance teams are starting to ask the same questions they ask about any other system: who called this, what did it see, can you prove it.
OPA, service meshes, proper secrets management — Kubernetes gives you a real place to enforce all of that, instead of bolting it on later.
Result: something your security team can actually sign off on.
Where this shows up in practice
- Enterprise copilots — RAG plus scalable inference, with each business unit getting its own slice without ten separate clusters.
- Autonomous agents — long-running, tool-using workflows that don’t fall over when something hiccups.
- Batch AI jobs — document processing, embeddings, fine-tuning runs that spin up huge for an hour and then vanish.
- Multi-model routing — sending easy queries to the cheap model, hard ones to the expensive one, with a fallback when a provider has a bad day.
- Edge and hybrid AI — K3s out in the factory or store, central control plane back at HQ.
The shift nobody’s really naming
For a long time, the platform team’s job was to run applications well. That job is changing. Now you’re running intelligence — models, agents, prompts, embeddings, evals and you have to treat all of it the way you treat code. Versioned. Deployed. Monitored. Rolled back when it breaks.
Kubernetes isn’t the exciting part of that story. It’s just the part that actually has to work.
So what’s the real question?
It’s not “which model should we use?” That answer changes every six weeks anyway.
he real question is: how do we run intelligence at scale, without it falling apart the moment real users show up?
That’s a Kubernetes question.