
For years, the concept of self-healing infrastructure has long hovered in the realm of science fiction- a system that detects its own failures and automatically repairs them, like a digital immune system. Is this just an operational fantasy or is it an achievable reality? The answer varies; but it is a practiced reality today, and it’s a journey, not a destination.
The Reality: Automation, Not Autonomy
True autonomous systems that can instinctively detect and fix unknown problems remain a future goal. However, self-healing in practice means creating the systems that can automatically respond to the known failure modes through pre-defined playbooks. But the initial goal is to reduce human intervention, minimize downtime (MTTR – Mean Time to Repair), and allow engineers to focus on innovation rather than firefighting.
A Guiding Framework: Chaos Engineering at Netflix
No example illustrates this better than Netflix’s pioneering work in Chaos Engineering. They had their infamous Chaos Monkey—a tool which randomly terminate instances in production— forced them to build resilience from the ground up.
How it Works:
- Hypothesize: Assume a component (e.g., a database replica, or an instance) will fail.
- Blast Radius: Define and limit the scope of the experiment in which it will terminate.
- Run Experiment: Automatically kill the replica in production.
- Automated Response: The system detects failure via health checks and defined metrics.
- How to Heal? Use automated playbooks:
- Redirecting the traffic to healthy nodes.
- Launch a new instance from a pre-configured AMI.
- Re-integrate the instance into the load balancer pool.
- Everything is done without paging an engineer.
This framework transforms resilience from a theoretical concept into a continuously tested, automated reality.
The Anatomy of a Self-Healing Loop (A Simple Diagram)
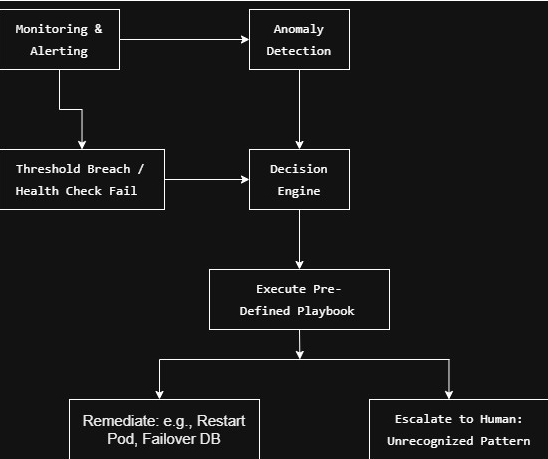
Measurable Impact: The Metrics That Matter
While specifics are guarded, the industry report tangible outcomes when implementing these patterns:
- MTTR Reduction: Most teams often see MTTR for common issues to drop from hours to minutes or to even seconds. For example, an automated pod restart in Kubernetes can remedy a memory leak in under 3 minutes.
- Alert Fatigue Reduction: By automating the responses to “noisy” alerts (e.g., service restart), a major e-commerce platform reported a 40% decrease in low-level operational alerts reaching the engineers.
- Increased Release Velocity: Carrying this confidence in automated rollback and remediation, deployment frequencies can be increased safely.
Candid Challenges: The “Myth” Part most ignore
It’s crucial to be honest about the hurdles:
- Complexity & Initial Cost: Building observability, decision engines, and reliable playbooks requires significant upfront investment in tools, skills, and time. The diagram above looks simple, but implementation is complex.
- The “Known Unknowns” Problem: The automated system will excel at fixing anticipated failures. A novel, multi-component cascading failure will still require human ingenuity. Self-healing handles the predictable; humans are needed for the unpredictable.
- Potential for Cascading Errors: A poorly designed playbook can make things even worse. Automating the wrong response (e.g., aggressively restarting a struggling service cluster-wide) can amplify an outage and cause major data loss.
- Cultural Shift: It requires a move from the “hero culture” (fixing things manually) to a “builder culture” (building systems that fix themselves), which is a profound change for many organizations.
Conclusion
Self-healing infrastructure is a reality, but it is not magic dust. It is the result of deliberate engineering choices: comprehensive observability, infrastructure-as-code, immutable artifacts, and most importantly the cultural adoption of practices like Chaos Engineering. It is about creating systems that are resilient by design, capable of automated surgery for common ailments, while still relying on human experts for the rare and complex diagnoses. The journey begins not by seeking autonomy, but by automating the most tedious, repetitive, and operational tasks consuming most of the time. That’s where the real healing starts.


