


Dashboards as a Code: Automating Grafana Dashboard Management Across Environments
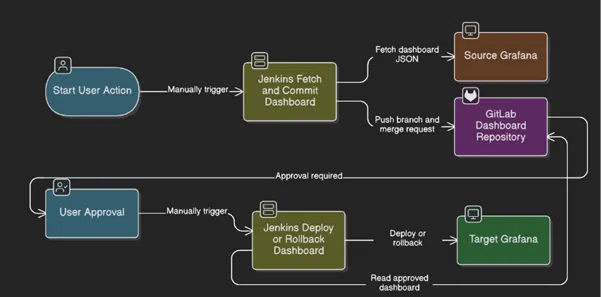
The workflow orchestrates several key technologies:
Jenkins functions as the automation engine that controls two different pipelines for dashboard fetching/committing and deployment handling.
There are two different environments for Grafana instances:
A source instance where dashboards are created and tested, and a target instance where dashboards are deployed or rollbacked. GitLab acts as the version control system where all dashboard changes are tracked and it is also the single source of truth for all dashboard configurations.

As a CloudOps Engineer, I focus on building and managing scalable cloud infrastructure. My role involves cloud deployments, infrastructure management, monitoring, and automation to ensure reliable and efficient cloud operations. I also work with DevOps practices and automation tools to support modern cloud-native applications and improve operational efficiency. Passionate about AI and data-driven technologies, I continually explore new ways to build scalable, innovative cloud solutions.

