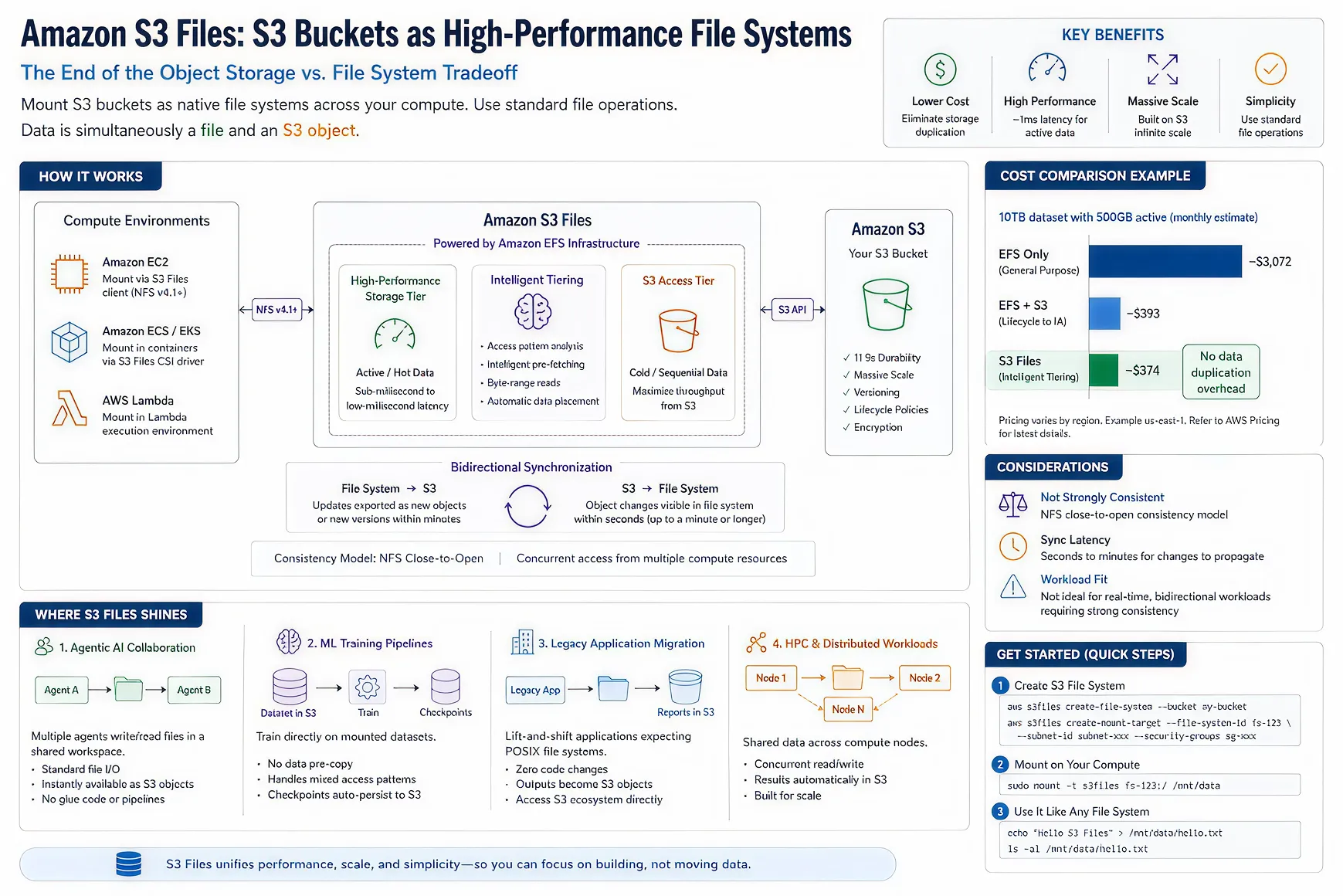
AWS just collapsed a tradeoff that’s shaped cloud architecture for 15 years.
If you’ve built anything serious on AWS, you know the pattern.
Need scale, durability, and low-cost storage? Use S3.
Need a real file system your applications can actually work with? Use EFS.
And if you needed both, you built pipelines to move data between them and accepted the operational overhead that came with it.
That compromise is finally starting to disappear.
With Amazon S3 Files, AWS now lets you mount an S3 bucket and access it like a native file system. Same bucket. Same objects. But applications can now read and write using standard file operations.
It sounds like a small feature update.
It isn’t.
Why this matters more than it looks
Most enterprises end up running multiple storage layers in parallel:
- S3 for large-scale object storage
- EFS or FSx for POSIX workloads
- Separate storage environments for ML and AI pipelines
Then comes the glue:
- sync jobs
- copy scripts
- orchestration workflows
- Lambda functions that exist purely to move data around
Nobody intentionally designs this complexity. It accumulates over time because applications expect file semantics and S3 was never built for that model.
So teams kept solving the same problem in different ways.
S3 Files changes the direction completely.
Instead of moving data closer to applications, applications can directly access data inside S3.
One source of truth. Multiple access patterns:
- S3 APIs for object access
- Iceberg and query engines for analytics
- S3 Files for file-system-based workloads
That’s a much cleaner architecture than what most enterprises operate today.
What’s happening under the hood
AWS is essentially using EFS infrastructure to layer file-system semantics on top of S3.
Services like:
- EC2
- ECS
- EKS
- Lambda
can mount S3 buckets directly.
Hot data gets cached for faster access. Cold data streams from S3 as needed. Prefetching helps improve sequential workloads.
The important part is this: your applications don’t need to understand any of that complexity.
They just see files.
Where this becomes powerful
AI and Agentic Architectures
This is probably the most obvious use case.
AI systems constantly move:
- embeddings
- checkpoints
- datasets
- context files
- intermediate outputs
Today, those workflows involve too many copies and too much orchestration.
With S3 Files, AI agents and ML systems can directly work against shared S3 datasets without staging data into separate environments first.
That means:
- fewer duplicated datasets
- simpler orchestration
- less operational overhead
ML Pipelines
ML teams spend an enormous amount of time moving datasets before training even starts.
Now training workloads can potentially operate directly against mounted S3 datasets while persisting outputs back into the same storage layer.
Less copying. Less storage duplication. Simpler pipelines.
At scale, that matters.
Legacy Application Modernization
This may actually be the most underrated impact.
A lot of enterprise applications were built assuming POSIX file systems and simply don’t understand object storage APIs.
Until now, companies had two bad choices:
- rewrite the application
- maintain parallel file systems forever
S3 Files introduces a third option:
keep the application behavior while modernizing the storage layer underneath.
That’s a much more practical modernization path for many enterprises.
A few honest caveats
This is not a silver bullet.
S3 Files uses NFS close-to-open consistency, so updates are not instantly visible everywhere. Highly transactional and latency-sensitive workloads will still need specialized storage architectures.
AWS is pretty transparent about that, and enterprises should be realistic about workload fit before adopting it broadly.
The real story here
S3 has quietly been evolving into the universal data layer for years.
Analytics.
Data lakes.
Table formats.
AI workloads.
Now file-based access patterns.
S3 Files is another step in that direction.
But the biggest advantage may not be performance or scale.
It’s simplicity.
Fewer silos.
Less data movement.
Less operational drag.
And in cloud architecture, reducing complexity usually creates more long-term value than adding another shiny feature.
At Anblicks, this is exactly the kind of architectural shift we pay attention to — not because every new cloud feature changes the game, but because some of them genuinely reshape how modern platforms should be built.
We continuously evolve our cloud, AI, and data modernization strategies to help enterprises adopt the right innovations without disrupting what already works.