
The Real Problem with IoT Testing Today
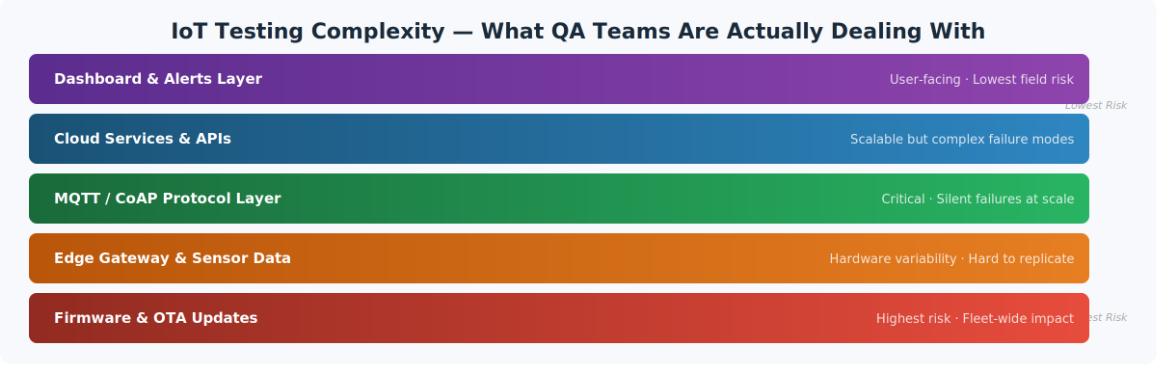
Figure 1 — IoT testing spans five distinct layers, each with different failure modes and field impact
Most IoT QA teams fall into one of two habits when time is running out. Either they rush through the full suite and accept that some things get a surface-level pass, or they informally skip lower-priority test cases and rely on the senior tester’s instinct to catch what matters. Both are understandable given the constraints. Neither is great.
The informal approach works better than it sounds, an experienced QA person develop a decent radar for risk. The problem is that it is not consistent. It depends on what happens in that sprint, what they remember from the last release incident, and whether they have time to look at recent commit activity. That is not a scalable process.
Why AI Handles IoT Risk Prioritization Better Than Humans Can Alone
Risk-based testing works reasonably well for web applications because the dependency is manageable and most of the relevant context is available in a few places. IoT breaks that.
Dependency runs deeper, hardware introduces inconsistency that software testing cannot always replicate, and the data you need to make a good risk decision is scattered – some in Git, some in Jira, some buried in field telemetry logs that nobody has time to read before standup.
No single person can process a massive web of variables simultaneously, making this the perfect problem to offload to AI.
Rather than trusting strictly to memory and subjective judgment, teams can pull modification history, component-specific bug metrics, and field incident logs into an algorithmic framework that assigns a risk score to all testing areas at the start of every sprint.
The technology is not a replacement for the skilled tester, but it is giving that tester a faster, more consistent starting point.
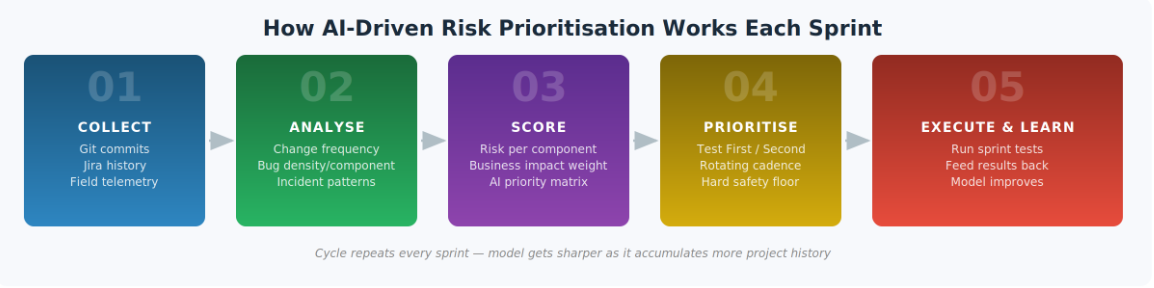
Figure 2 — The five-step AI prioritizsation loop, executed at the start of each sprint
What collaborative units can logically project as their return?

Figure 3 — Key metrics from teams that have adopted AI-driven risk-based testing


