


Traditional RAG follows a simple loop:
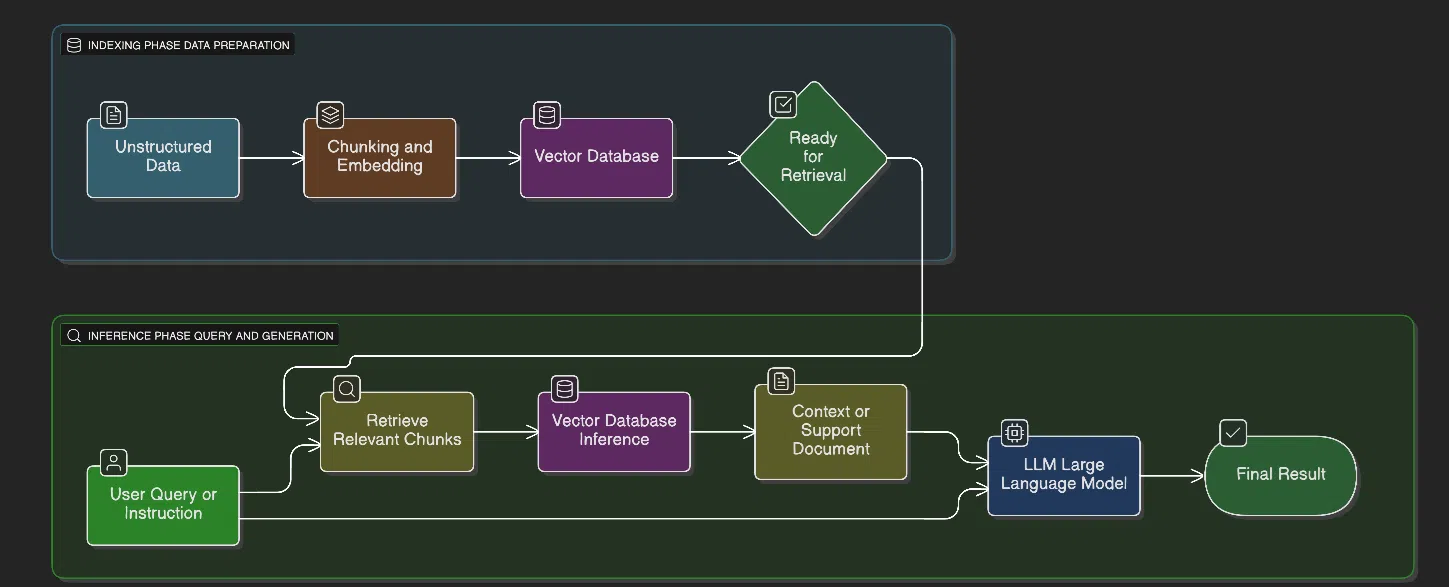
- Retrieve relevant documents
- Feed them into an LLM
- Generate an answer
RAG retrieves relevant text, but not relationships. Vector databases help, but they aren’t perfect.
Chunking is always a tradeoff:
- Large chunks → more context but more noise
- Small chunks → cleaner but missing details
- Too much metadata → inefficiency
No chunk size solves all problems.
However, it has limitations:
- No understanding of relationships: LLM can read text about “Service A depends on Service B” but cannot reason graphically.
- Fails on multi-hop reasoning: Example: “If Database X goes down, which business units are impacted?” Traditional RAG retrieves isolated chunks—it does not compute dependency chains.
- Inconsistent answers: Different documents may contradict each other; RAG does not unify facts.
- Lacks explainability: Retrieval shows chunks, but cannot show why the model reached a conclusion via logical paths.
- Poor fit for structured interconnected enterprise data
This gap is exactly what Knowledge Graph RAG is designed to fix.
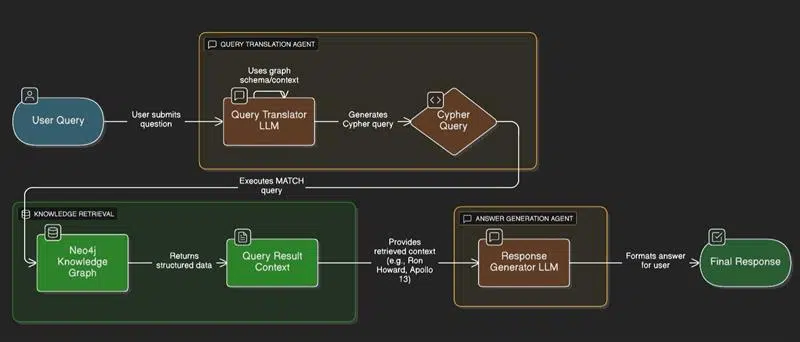 Knowledge Graph RAG.md
Knowledge Graph RAG.md
User Query:
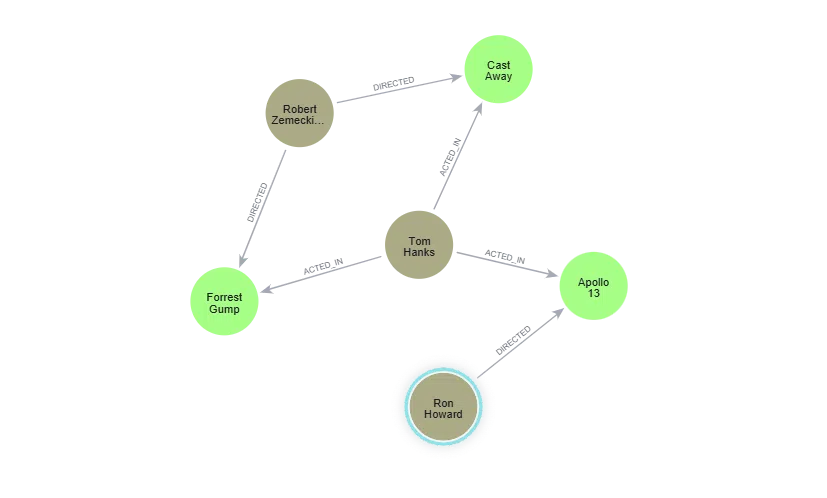
“Who directed the movie Tom Hanks acted in where he played the character ‘Jim Lovell’?”
Final Response:
“The movie Tom Hanks acted in, where he played the role of Jim Lovell, was Apollo 13, and the director was Ron Howard.”

As a Principal Software Engineer at Anblicks, Vinit Prajapati specializes in leading enterprise application development, translating complex business needs into robust, growth-oriented technical solutions. His 15+ years in the IT industry are defined by extensive expertise in advanced web and cloud native applications, and intelligent application development.

