


From Decision Exhaust to Intelligent Enterprise Architecture thru Ontology & Palantir
In the first article, I introduced the idea that most enterprises stop at automation, but very few become truly intelligent machines.
Over the past few decades, enterprises have invested heavily in ERP modernization, cloud data platforms, AI capabilities, BI dashboards etc. Yet still during peak operational periods, most organizations still rely on spreadsheets, escalation emails, war-room meetings, and manual overrides.
Most companies automate tasks. Very few redesign how decisions are made, governed, executed, explained, and learned from.
In this article, I would like to explore this further on what does it actually take to implement an Intelligent Enterprise architecture. To illustrate this, I would like to use Palantir as an example. This also helps clarify what #palantir does since most people still think palantir just as yet another data or AI platform. In reality, it is a system that models how a business operates so decisions can be made, executed, and learned from end-to-end.
How do data, decisions, workflows, GenAI, and enterprise integrations come together into a single Palantir system?
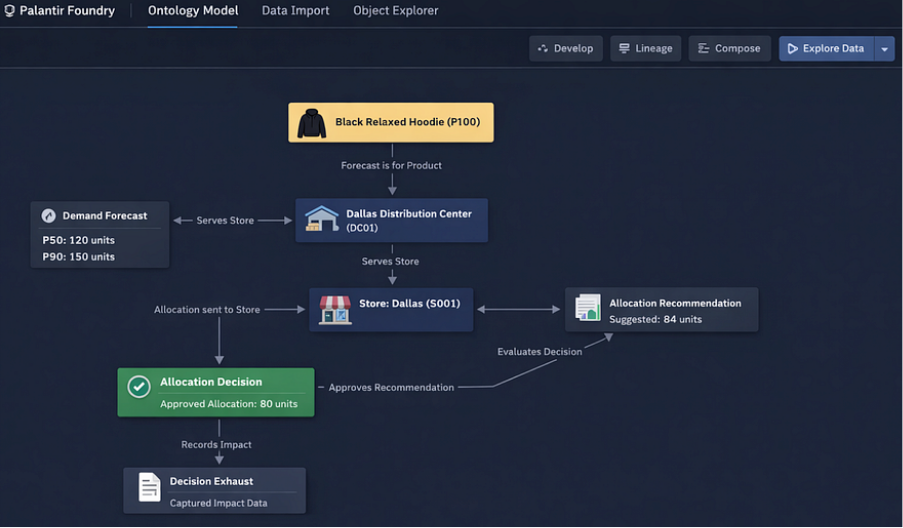
These objects form the digital twin of the enterprise — a living model of business operations that applications, workflows, and AI systems operate on.
2. Define Relationships in Business Language
Relationships between ontology objects are defined using link types, which are expressed in plain business language.
Examples:
- Forecast is for Products
- Forecast is for Stores
- Stores is served by Distribution Center
- Distribution Center fulfills Stores
- Recommendation suggests allocation for Stores
- Decision approves Recommendation
- Decision applies Policy Rule
- Outcome evaluates Decision
These relationships are not just structural. They are semantic and readable. In cases where relationships require context, object-backed links are used. This allows relationships themselves to carry business operational meaning.
3. Build Data Pipelines, Lineage, and Context
All business operational data flows through pipelines built in #palantir Foundry using:
- Pipeline Builder
- Code Repositories (Python / Spark / SQL)
Typical data sources:
- POS transactions
- Inventory snapshots
- Shipments
- Promotions
- Capacity data
- Vendor inputs
Pipelines transform these into structured datasets for demand planning, forecasting and optimization.
Every dataset is fully traceable through Data Lineage:
- Upstream source
- Transformation logic
- Downstream consumers
AI is embedded directly in pipelines to process unstructured inputs:
- Extract promotion details from documents
- Classify vendor communications
- Summarize operational notes
- Normalize free-text inputs into structured signals
This ensures the operational graph can tap into organizational intelligence in the form of both structured and unstructured data.
4. Demand Planning, Forecast Generation and Model Lifecycle
Forecasts (P50, P90) are generated using machine learning models built and managed in #panatir Foundry.
Example:

Kumar Raman is the Chief Product and Technology Officer with over 20 years of experience in Data, Analytics, and AI leadership. He specializes in shaping AI-driven data strategies, modern architectures, and large-scale transformation initiatives that deliver measurable business outcomes. Kumar has led multimillion-dollar programs, modernizing data platforms and embedding AI into enterprise decision-making. He is also a trusted advisor to executive leadership, helping organizations accelerate their journey toward intelligent, AI-powered operations.

