


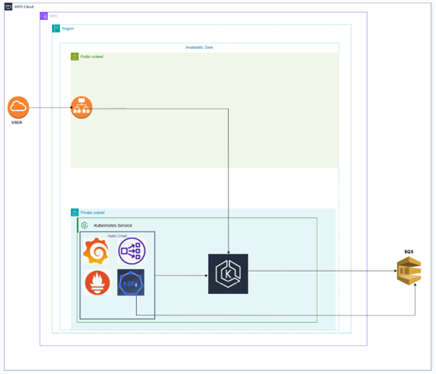
The architecture is intentionally simple but representative of real-world asynchronous systems. The system is made up of four core components:
- A simple web interface for submitting messages
- An Amazon SQS queue that decouples ingestion from processing
- Kubernetes worker pods that process messages
- KEDA, which monitors the queue and adjusts scaling accordingly
When a user submits a request, a message is placed into SQS. The request is acknowledged immediately, which is good for the user experience as it stays responsive. Worker pods run inside a Kubernetes cluster and continuously poll the queue. These workers do not scale based on CPU or memory usage. Their replica count is driven entirely by queue depth.
KEDA is the layer that integrates SQS and Kubernetes. It keeps an eye on queue metrics and changes the number of worker pods on the fly. This clear separation of components makes the system stable, resilient, and user-friendly. Combination of Prometheus and Grafana was utilised for monitoring purposes.

As a CloudOps Engineer, I focus on building and managing scalable cloud infrastructure. My role involves cloud deployments, infrastructure management, monitoring, and automation to ensure reliable and efficient cloud operations. I also work with DevOps practices and automation tools to support modern cloud-native applications and improve operational efficiency. Passionate about AI and data-driven technologies, I continually explore new ways to build scalable, innovative cloud solutions.

